The Kinetic Banking When Your Bank Stops Guessing and Starts Knowing

Let’s be honest. Most banks treat you like a segment. “You’re a millennial with a checking account? Here’s the same savings pitch we sent to 47,000 other millennials.” It’s not personal. It’s not smart. And it’s definitely not the future.
The Kinetic Banking is different. It’s a full-stack showcase of what happens when you treat banking as an operating system — a platform where data flows, decisions are orchestrated, and the system learns from every interaction. No black boxes. No one-size-fits-all. Just a bank that gets smarter the more you use it.
Here’s how it works, why it matters, and what we actually built.
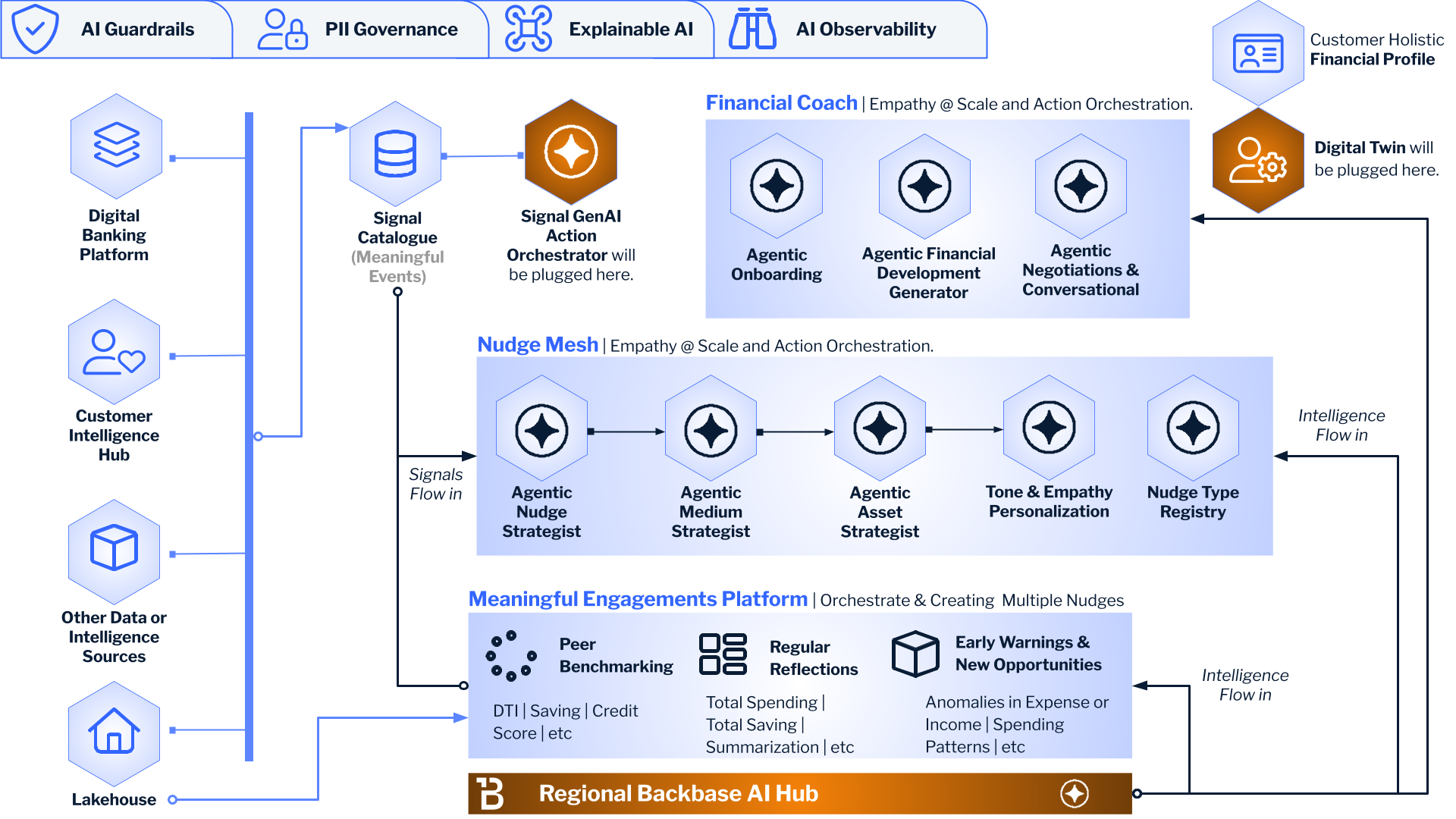
Think of your phone. iOS or Android doesn’t care what app you’re in — it provides a layer of services (notifications, storage, identity) that every app taps into. Banking should work the same way. A Banking is the underlying platform: the shared source of truth, the decision engines, the event backbone. The apps — checking, savings, loans, financial coaching — sit on top.
The Kinetic Banking showcase proves this isn’t vapourware. It’s a working demo with six interconnected layers, real data flow, and an open-source stack you can run on your laptop. Kafka, PostgreSQL, Neo4j, MLflow, dbt, Feast, OPA — the whole gang.
The Six Layers
The Idea Machine
This is where the magic starts. Raw data from your core banking system flows through a pipeline: Mifos-like mock → Kafka → dbt → Feast → Neo4j → MLflow → LangGraph → OPA. Each step transforms, enriches, or constrains. dbt builds the semantic layer — fct_customer_health with balance, savings, transaction counts. Feast defines the features. Neo4j holds the ontology: which actions exist, which life-stages trigger them, how domains map to recommendations. MLflow tracks every decision. OPA enforces guardrails before anything goes out the door. By the time we get to "what should we recommend?", we're not guessing. We're deciding based on a semantic understanding of your behaviour, your life stage, and the ontology of possible actions.
We call it the Idea Machine because it doesn’t produce one product for 100,000 people. It produces one recommendation for one person. N-of-1. That’s the goal. The name isn’t marketing fluff — it’s literally a supply chain for ideas. Raw data in, personalised decisions out.
The Nervous System
Every channel — mobile app, call centre, branch, AI coach — needs the same view of the customer. Not 12 different databases with 12 different “truths.” One. The Shared Source of Customer Truth is that single source. RudderStack for identity resolution, OpenSearch for semantic search, PostgreSQL for decision history, Kafka for real-time events. When the CLO (Customer Lifetime Orchestrator) or the Financial Coach asks “who is this customer?”, they get the same answer. Always.
The Engine
The CLO is your Next-Best-Action brain. It routes customers by life stage: Acquisition (just signed up), Activation (first account, first transaction), Expansion (ready for savings, cards, loans), Retention (at risk, need love). For each domain, it picks the right action from a knowledge graph in Neo4j — not hardcoded rules, but an ontology of actions, entities, and triggers. “Sarah has a current account and a term deposit? She’s in Expansion. The ontology says she hasn’t done add_card yet. Recommend that.” Simple. Auditable. Driven by the graph.
The Empathetic Advisor
The Coach is different from the CLO. The CLO sells. The Coach coaches. Five domains: Health Assessment, Anomaly Detection, Peer Benchmarking, Early Warnings, Weekly Reflections. It reads from the same Customer Truth but acts as an empathetic AI advisor. “Your financial health score is 72. You’re doing well — consider setting up automatic savings.” No product pitch. Just insight. The Coach can chat (LangChain) or nudge (transactional, budget, FDP, insights). Same data, different intent.
The Gentle Push
Nudges are the Coach’s output. Transaction-based (“That restaurant charge was 40% higher than usual — was that you?”), budget alerts, goal-based recommendations, personalised insights. They’re delivered via the nudge service and can flow to Kafka for downstream channels (push, in-app, email). The key: they’re actionable. Not “here’s a chart.” “Here’s what to do next.”
Augmented Intelligence
This is where the bank learns. Every decision — every NBA, every nudge — gets published to Kafka (decisions.outcomes). A writeback consumer persists it to PostgreSQL (Decision History), updates customer state, and triggers MLflow for retraining. The next time we recommend something, we're not flying blind. We know what worked before. Augmented Intelligence means the AI is augmented by feedback. The bank gets smarter. Not in theory. In practice.

The Showcase Tech Stack
- Mifos-like mock — REST API for clients, accounts, transactions. Emits to Kafka on every create/update. Swappable for real Mifos/Fineract later. No vendor lock-in on the core.
- Apache Kafka — Event backbone. Topics: mifos.clients, mifos.accounts, mifos.transactions, decisions.outcomes. Events flow one way. Consumers do their thing. Decoupled, scalable, boring in the best way.
- PostgreSQL — Customers, accounts, transactions, decision history. The source of truth for structured data. The Kafka consumer writes here. The Customer Truth API reads from here. Simple.
- OpenSearch — Entity resolution, semantic search. “Find customers like Sarah.” When you have 10 million customers and need to match identities across systems, this is your friend.
- Neo4j — Ontology. Actions, entities, concepts. Life-stage triggers actions. Domain maps to recommendations. The CLO doesn’t hardcode “if Expansion then suggest add_card.” It queries the graph. Change the ontology, change the behaviour. No redeploy.
- dbt — Semantic layer. stg_customers, stg_accounts, fct_customer_health. Clean, tested, versioned. The kind of data engineering that doesn't give you nightmares at 2am.
- Feast — Feature store. Customer health features for the Coach and ML models. In production you’d have hundreds of features. For the demo we’ve got the schema. The pattern holds.
- MLflow — Model registry, experiment tracking. Every CLO decision, every Coach nudge, every writeback — logged. The kinetic-decisions experiment is where you see it all. Params, metrics, tags. No more "what did we recommend last Tuesday?" — it's all there.
- OPA (Open Policy Agent) — Guardrails. “Don’t recommend if account is closed. Don’t recommend if confidence < 0.7.” Policy as code. Change the Rego file, change the rules. No engineering ticket.
- Next.js — The showcase UI. Layer Explorer, Run Demo, Chat, Event Stream. All in one place. Dark theme. Cyan accents. You know the vibe.

The Philosophy
Three pillars underpin the architecture. They’re not buzzwords. They’re design principles that show up in the code.

The Idea Machine — The Intelligence Supply Chain is the Idea Machine. Data flows through to N-of-1 decisions. Not a product for 100,000 people. One product for one person. The pipeline exists to manufacture ideas: the right recommendation, the right nudge, at the right time. If your “personalisation” engine recommends the same thing to everyone in a segment, you don’t have an Idea Machine. You have a mail merge.
Data Mesh — The Shared Source of Customer Truth is the Data Mesh. Domain-owned data products feeding a real-time, unified semantic view. The Digital Twin depends on it. Each domain (CLO, Coach, core banking) produces data. That data flows into a unified layer. No single team owns “the customer” — but everyone consumes the same view. That’s the mesh. That’s how you avoid the 12-database problem.
Augmented Intelligence — The Outcome Feedback Loop + Decision History is Augmented Intelligence. Every AI decision stored, auditable, used to retrain. The bank learns from every interaction. “Augmented” means the AI is augmented by feedback. Not just by better models. By knowing what happened when we recommended X. Did they take it? Did they ignore it? That’s the loop. That’s how you stop making the same mistake twice.
Sarah’s Story
We built a demo customer: Sarah Chen. She onboarded two months ago, opened a current account with a beautiful number (***932021), got offered a term deposit at 4.5% APY, took it. Six weeks later, we offered a credit card with Apple Pay. She took that too. Her journey is in the data: sign_up → open_current_account → complete_onboarding → open_term_deposit → open_credit_card. Each step is a decision. Each decision is in the history. Each flows through the pipeline.
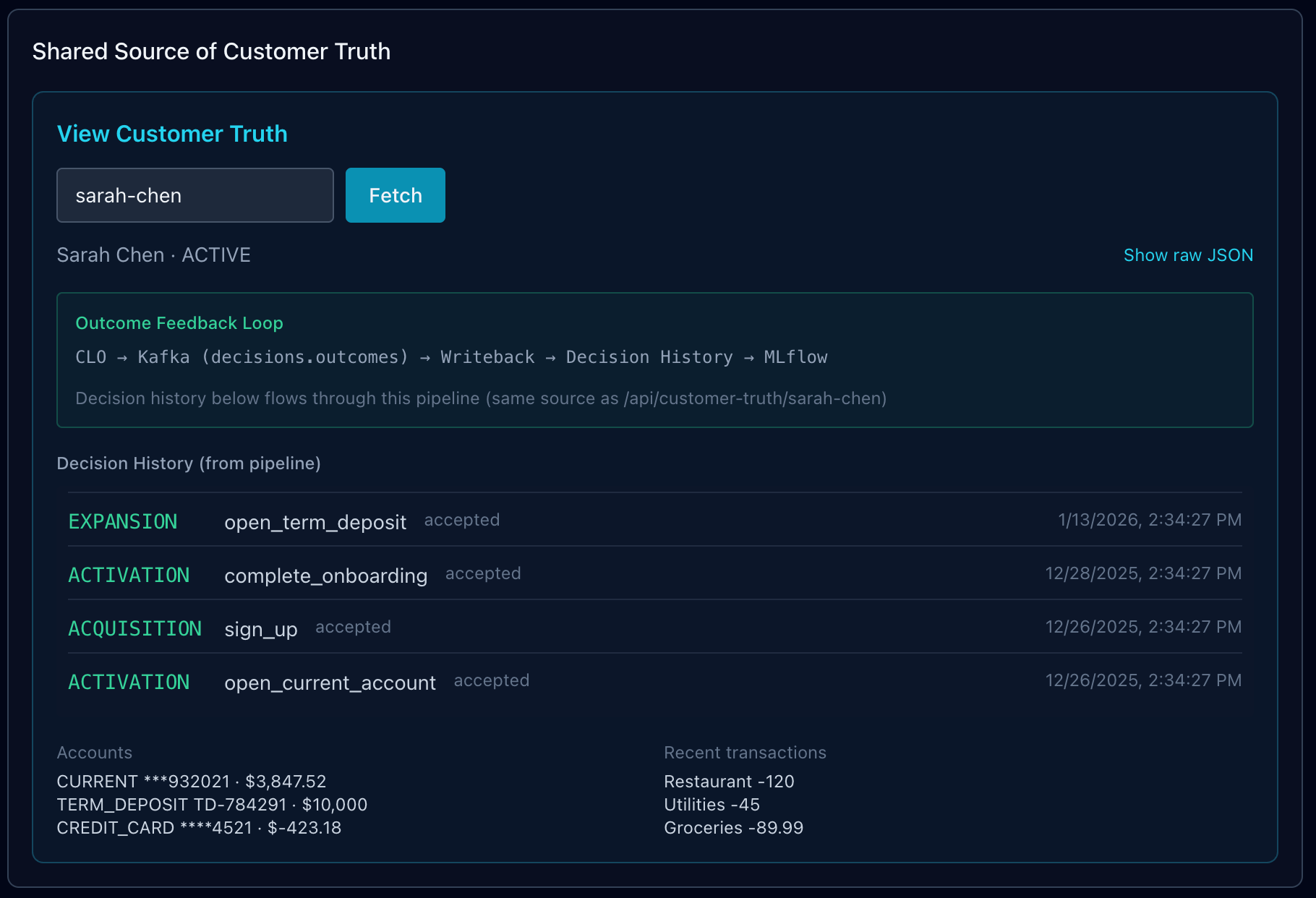
When you hit Run Demo, we seed Sarah, get an NBA from the CLO (ontology-driven — Neo4j tells us what to recommend next), generate a Coach nudge, and show the feedback loop. The decision goes to Kafka. Writeback persists it. MLflow logs it. You can see it all: Customer Truth, Layer Explorer, Event Stream, MLflow. One click. Full loop.

The beauty of Sarah’s story is that it’s realistic. She’s not a synthetic blob of attributes. She has a current account with a memorable number (because banks do that). She has a term deposit because we offered her a good rate at the right moment. She has a credit card because we caught her in Expansion and the ontology said “add_card” was the next best move. The pipeline orchestrated it. The feedback loop recorded it. Next time we’ll know what worked.
Why This Matters
Banks have been doing “personalisation” for years. Usually it means “we have a segment and we’ll A/B test a subject line.” That’s not personalisation. That’s segmentation with extra steps. It’s also why most bank apps feel like they were designed by a committee that never met a human.
Real personalization requires:
- One truth — Every system sees the same customer. No more “the mobile app says you have $500, the call centre says $200, and the statement says something else.” One source. One answer.
- Semantic understanding — We know what actions mean, what life stages imply, what triggers what. The ontology isn’t a nice-to-have. It’s the difference between “recommend something” and “recommend the right thing.”
- Feedback — We learn from outcomes. We don’t repeat mistakes. The Outcome Feedback Loop isn’t a dashboard. It’s the mechanism by which the bank gets smarter. Every decision logged. Every outcome fed back. Retraining triggered. Rinse, repeat.
- Guardrails — We don’t recommend to closed accounts. We don’t recommend low-confidence garbage. OPA sits in front of every decision. Policy as code. Auditable. Changeable without a release.
The Kinetic Banking does all of that. It’s a showcase. It’s a blueprint. It’s proof that Invisible Banking isn’t a slide deck — it’s something you can run, extend, and learn from. The architecture is open. The stack is open source. The philosophy is clear: Invisible Banking means the intelligence is there when you need it, invisible when you don’t. The Kinetic showcase is step one.
https://github.com/chrisshayan/kinetic-banking
The showcase is live. The Run Demo works. The ontology drives the CLO. MLflow tracks everything. The next steps are obvious: more Coach domains, richer Feast features, production hardening. But the architecture is there. The loop is closed. The bank learns.
If you want to see it yourself: docker compose up -d, pnpm writeback, pnpm isc:seed-ontology, pnpm showcase. Open http://localhost:3000/demo. Hit Run Demo. Watch the pipeline breathe.
That’s the Kinetic Banking. Not a product for 100,000 people. A platform for one person at a time — and a bank that gets smarter every time.

The repo is open. The architecture is documented. The Run Demo is one click away. If you’re building the next generation of banking — or just curious what “Banking OS” actually means when you strip away the slides — this is where you start. Docker up, writeback running, ontology seeded. Hit the button. Watch the loop close. Then go build something better.