Here’s a scene I’ve witnessed at every bank I’ve worked with — from Vietnam to Europe and everywhere in between. The risk team pulls up their dashboard and it says the bank has 1.2 million “active customers.” Marketing opens theirs and counts 1.8 million. Then an AI pilot querying the raw data warehouse comes back with 940,000. Same bank. Same quarter. Three different truths.
The problem isn’t that people are bad at math. The problem is that each team defined “active customer” inside their own tool — their own Tableau workbook, their own Power BI model, their own SQL query. The metric logic is trapped inside the visualization layer. It was born there, it lives there, and it dies there when someone switches to a new tool or builds a new dashboard.
For years, this was an inconvenience. Teams argued in steering committees, reconciled numbers manually, and moved on. But that era is ending — fast.
When you introduce AI agents into this picture — agents that autonomously recommend products, generate campaigns, and coach customers on their financial wellbeing — fragmented metric definitions stop being an inconvenience and become an existential risk. An AI agent confidently acting on the wrong definition of “at-risk customer” isn’t a reporting discrepancy. It’s a customer experience failure at scale.
Recent research makes this painfully concrete. When large language models are tasked with generating SQL from raw database schemas — without any semantic guidance — accuracy rates can be as low as 17%. The model doesn’t know that “monthly active users” at your bank excludes internal test accounts, or that “revenue” nets out promotional cashbacks. It guesses. And it guesses wrong.
Dashboards aren’t the problem. Dashboards are still incredibly valuable for the humans who use them — for branch managers reviewing portfolio performance, for executives tracking strategic KPIs, for risk teams monitoring exposure. The problem is that we’ve been building our metric definitions inside dashboards instead of underneath them.
It’s time to set those metrics free.

Ankur Goyal and Alana Anderson
Headless BI: Define Once, Serve Everywhere
Headless BI is an architecture that decouples the semantic modeling and metrics definition from the data visualization layer. Instead of each BI tool owning its own version of how metrics are calculated, you establish a single, centralized layer — a shared semantic foundation — that defines every metric once. That layer then exposes those governed definitions via APIs. Any consumer can access them: dashboards, mobile applications, spreadsheets, internal tools, chat interfaces, and — critically — AI agents.
The concept isn’t entirely new. If you’ve worked in modern software architecture, the pattern will feel familiar. Think about what happened when banks moved from monolithic applications to microservices and API-first platforms. The functionality didn’t disappear — it was decoupled from any single front-end. The same business logic that powered a branch teller’s screen could now power a mobile app, a third-party integration, or an automated workflow. The engagement layer was liberated from the delivery channel.
At Backbase, we lived this transformation firsthand. Our entire thesis — re-architecting banking around the customer — was built on decoupling the digital engagement layer from monolithic core banking systems. One platform, many channels. The same account opening journey that works on a mobile device also works on the web, in a branch, and through an API.
Headless BI applies the same principle to intelligence. The metric is defined once. It’s governed in one place. And it’s served to every consumer — human or machine — through a consistent API. The dashboard still gets it. The mobile banking app gets it. The relationship manager’s CRM view gets it. And now, the AI agent gets it too.
This is the shift. It’s not about replacing dashboards. It’s about ensuring that dashboards are one of many first-class consumers of the same governed truth — not the sole owner of it.
When you structure your intelligence layer this way, something powerful happens: adding a new consumer — a new AI agent, a new internal tool, a new partner integration — doesn’t require rebuilding metric definitions from scratch. You plug in, and the truth flows.

Why This Matters Now
Headless BI as a concept has been gaining traction for a few years now. So why does it suddenly feel urgent? Because the nature of who — and what — consumes analytics is fundamentally changing.
For most of BI’s history, the consumer was a human being looking at a screen. A dashboard. A report. A spreadsheet. The human brought context, judgment, and institutional knowledge to the data. If the dashboard said something slightly off, an experienced banker would catch it. They’d know that the number looked wrong, ask questions, and reconcile. The system could afford to be messy because humans were the error-correction layer.
AI agents don’t have that luxury. An agent doesn’t “feel” that a number is off. It takes the data it’s given, applies its reasoning, and acts — with the confidence and speed that makes AI powerful, and that makes bad data dangerous. When an AI agent generates a personalized financial plan based on a flawed definition of “savings rate,” it doesn’t second-guess itself. It delivers that plan to thousands of customers before anyone notices.
This is the inflection point. We’re moving from a world where analytics was consumed by humans who could compensate for inconsistency, to a world where analytics is consumed by autonomous agents that amplify inconsistency.
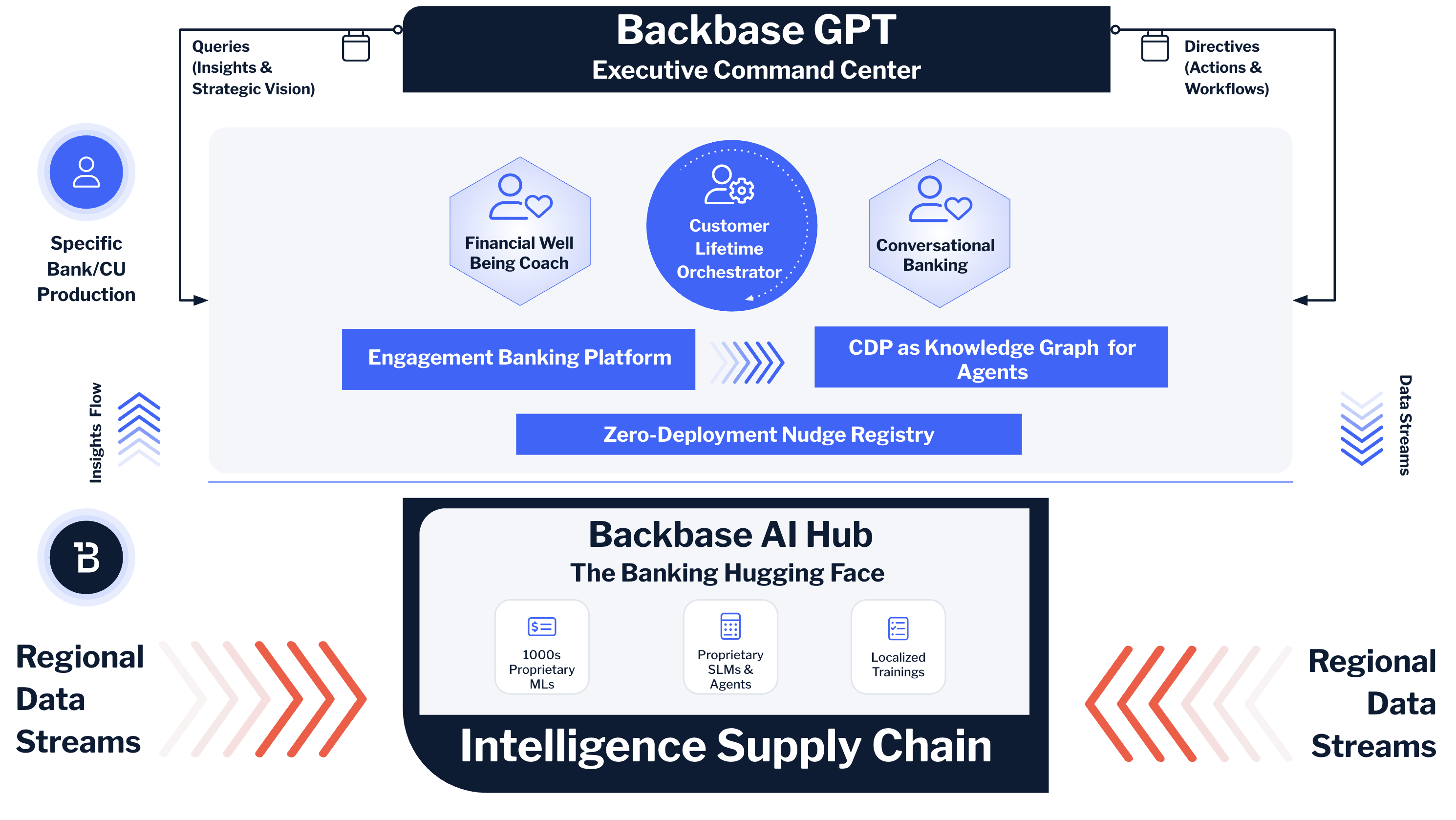
At Backbase, this realization has shaped how we’ve built the Intelligence Fabric — the data and AI layer natively embedded in our platform. The Intelligence Fabric acts as exactly this kind of governed semantic foundation: unifying behavioral signals, transactional data, product holdings, and operational insights into real-time, API-accessible intelligence. It feeds dashboards that relationship managers use in branch. It feeds the mobile banking experience that customers see on their phones. And it feeds the AI agents that are now beginning to act autonomously across the customer lifecycle.
The architecture is deliberate. Agents and humans are peers in how they consume intelligence. Neither gets a “special” or “different” version of the truth. They both draw from the same well.
Without this foundation, banks end up in a familiar trap: dozens of AI pilots running on fragmented data, each one producing subtly different results, none of them reaching production because the underlying truth isn’t consistent enough to trust at scale. I’ve seen this pattern repeat across three continents. The technology is ready. The data governance usually isn’t. Headless BI is the bridge.
Financial Wellbeing Coach — An AI Agent That Consumes, Not Displays
One of the things I enjoy about business trips is the uninterrupted time they provide for reading. On one of my longer trips, I read Peter Godfrey-Smith’s Other Minds: The Octopus, the Sea, and the Deep Origins of Consciousness. It’s a remarkable book. But what stayed with me — what I kept coming back to in my own work — was the octopus’s nervous system.
Two-thirds of an octopus’s neurons are in its arms. Each arm operates with a degree of autonomy, responding to local stimuli, making decisions independently. Yet they’re all connected to a central brain that provides coordination and context. It’s a decentralized architecture for consciousness — embodied, distributed, and deeply responsive to its environment.
That image has become my mental model for what we’re building with the Financial Wellbeing Coach at Backbase.
For years, the banking industry’s answer to “helping customers with their finances” was Personal Financial Management — PFM. And PFM, in practice, was a dashboard. It showed you pie charts of your spending categories. It displayed your account balances. It maybe let you set a budget. It was static, reactive, and — let’s be honest — boring. Most customers opened it once and never came back. The data was there, but it was locked inside a visual display that required the customer to do all the interpretation and all the work.
The Financial Wellbeing Coach flips this model entirely. It’s not a dashboard. It’s an AI agent that consumes the same governed metrics — financial health scores across savings, debt, insurance, and long-term wealth; spending behavior patterns; life-event triggers; income stability indicators — and uses them to reason, empathize, and guide.
It doesn’t show you a chart and hope you’ll figure out what to do. It notices that your emergency fund is three months behind where it should be relative to your income and fixed obligations. It connects that to the fact that you’ve had two unexpected medical expenses in the past quarter. And it proactively walks you through a plan — adjusting your savings allocation, suggesting a specific pocket for emergency reserves, and nudging you toward a health insurance product that could prevent the next shock.
This only works because the coach draws from a Headless BI layer. The financial health score it uses is the same score that appears on the customer’s dashboard in the mobile app. The spending categorization it reasons over is the same categorization that feeds the branch advisor’s CRM view. The debt-to-income ratio it evaluates is defined once, governed centrally, and served through an API. The coach doesn’t maintain its own version of the truth. It inherits the truth and adds intelligence on top.
And the vision extends further. We’re building toward a “web of coaches” — not just a financial wellbeing coach, but a property guru, a career advisor, third-party specialist agents — each operating with autonomy in their own domain, yet all connected to the same semantic foundation. Like the octopus: each arm acts independently, but they share a nervous system.
The Headless BI layer is that nervous system. Without it, each coach becomes an island — reasoning on its own data, arriving at its own conclusions, potentially contradicting the others. With it, you get distributed intelligence grounded in a single truth.
The old PFM was a dashboard — a “head” tightly coupled to its data. The new coach is headless: the intelligence is liberated, and the agent is just one of many consumers.
Customer Lifetime Orchestrator — When Many Agents Need One Truth
If the Financial Wellbeing Coach demonstrates why a single AI agent needs Headless BI, the Customer Lifetime Orchestrator demonstrates why a system of agents cannot function without it.
Let me explain the business context first, because — as I always say — you should always start with the business case.
Most retail banks are reasonably good at acquiring customers. Open an account, get a debit card, download the app. But the vast majority of value is captured after acquisition — in what products a customer adopts over time. The product holding ratio — the average number of products per customer — is one of the most reliable predictors of customer lifetime value. A customer with a checking account and a debit card has a fundamentally different relationship with their bank than a customer who also holds a credit card, a savings account, an insurance policy, and an investment portfolio. The latter is more engaged, more profitable, harder to churn, and cheaper to serve.
Yet most banks treat cross-sell and upsell as a manual, campaign-driven, one-size-fits-most exercise. A marketing team decides it’s “credit card month,” blasts an offer to a broad segment, and hopes for a conversion rate above 2%.
The Customer Lifetime Orchestrator replaces this approach with something fundamentally different. It generates personalized 90-day engagement plans for each customer and each product, designed to progressively increase product holding. But here’s the key architectural insight: the CLO is not a single model. It’s an orchestra of agents, each playing a different role.
There’s an ML model predicting the next-best-product for each customer based on behavior patterns, life stage, and financial profile. There’s a Gen AI agent generating personalized content — the nudge message, the educational micro-content that explains why a savings pocket matters for someone in their situation. There’s a digital marketing engine scheduling the delivery of those nudges across the right channels at the right time. There’s a key visual designer generating branded creative assets that match the bank’s brand guidelines for each product category. And there’s an orchestration layer coordinating the sequence — the 90-day phased plan that moves a customer from awareness through consideration to activation.
Now imagine what happens when these agents don’t share the same metric definitions.
The ML model defines “high-value customer” based on total balance and transaction frequency. The content agent defines it based on login recency and digital engagement. The marketing engine uses a third definition inherited from the legacy CRM. The result? The ML model identifies a customer as prime for a wealth product. The content agent writes a nudge for a basic savings account because its engagement data says the customer is dormant. The marketing engine delivers it to the wrong segment entirely. The 90-day plan doesn’t just underperform — it actively contradicts itself.
This is what Headless BI prevents. When every agent in the CLO ecosystem consumes metrics from the same governed semantic layer, the definitions of “active customer,” “high-value segment,” “product holding ratio,” and “engagement score” are identical everywhere. The ML model, the content agent, the marketing engine, and the key visual designer are all reading from the same score.
Let me walk through a concrete scenario. A retail bank wants to increase credit card activation among customers who onboarded in the last 90 days. The CLO pulls the governed definition of “activation” from the semantic layer — not just “card issued,” but “first transaction completed within 30 days of issuance.” It pulls behavioral signals: login frequency, spending patterns on the debit card, app feature usage. The ML model identifies which new customers have the highest propensity to activate if nudged. The Gen AI agent generates three variations of a personalized message, each calibrated to the customer’s communication preferences and financial profile. The key visual designer renders branded assets aligned with the credit card product’s marketing guidelines. The marketing engine schedules delivery across mobile push, in-app messaging, and email — phased over weeks, not blasted all at once.
Every participant in this workflow consumed the same definition of every metric involved. No reconciliation needed. No contradictions. No “which number is right?” meetings.
This is what I mean when I say the CLO mixes agents + ML + digital marketing + content + design into a unified system. The Headless BI layer is what makes it a system rather than a collection of disconnected tools.
Scaling the Ecosystem on a Shared Semantic Foundation
The Financial Wellbeing Coach and the Customer Lifetime Orchestrator are powerful — but they’re individual products. The real question for any bank is: how does this scale? How do you go from two AI-powered capabilities to twenty? To two hundred?
This is the question the Backbase AI Hub is built to answer.
Think of it this way. If Headless BI provides the governed data backbone, and the Coach and CLO are flagship agents consuming that backbone, the AI Hub is the marketplace where the ecosystem grows. It’s where banks discover, customize, and deploy pre-built agents and orchestration templates — purpose-built for banking, and pre-wired to consume from the same semantic layer.
I often describe it as the “Hugging Face of banking” because the analogy is precise. Hugging Face didn’t create every machine learning model in existence. What it did was build a platform where models could be shared, discovered, fine-tuned, and deployed by anyone — dramatically lowering the barrier to AI adoption for the entire ML community. A researcher in Tokyo and an engineer in Berlin could both find, evaluate, and deploy the same pre-trained model within minutes.
The AI Hub does the same thing for banking. A tier-2 retail bank in Southeast Asia and a credit union in North America can both discover a churn-prediction agent, a document verification agent, a financial coaching template, or a customer lifetime orchestration workflow — and deploy it into their own environment with confidence.
But here’s what makes the Hub fundamentally different from simply aggregating a bunch of AI tools: every agent in the Hub is designed to consume from the same governed semantic layer. This is the Headless BI principle at ecosystem scale.
Why does this matter? Because without a shared semantic foundation, a marketplace of agents becomes a marketplace of contradictions. Bank A deploys a churn-prediction agent from one provider and a next-best-product agent from another. If each agent brings its own metric definitions — its own notion of “churn risk,” its own calculation of “customer value” — the two agents will inevitably disagree. The churn agent flags a customer as at-risk while the product agent simultaneously tries to upsell them. The customer receives a retention offer and a cross-sell nudge in the same session. It’s not just inefficient — it erodes trust.
When every agent in the Hub inherits governed definitions from the same Headless BI layer, this problem dissolves. A bank can swap in a new churn-prediction agent, add a third-party specialist coach (like our Property Guru), or compose entirely new orchestration workflows — and every component plugs into the same truth. No metric migration. No reconciliation projects. No KPI chaos.
This also dramatically reduces the integration burden that kills most AI initiatives. I’ve seen banks spend 40 to 60 percent of their digital transformation budgets on integration alone — mapping data between systems, reconciling definitions, building custom pipelines. The Hub, built on a Headless BI foundation, shifts this from a per-agent integration problem to a one-time semantic alignment.
The compounding effect is significant. The first agent is the hardest — you’re establishing the governed semantic layer, aligning definitions, building the API contracts. The second agent is easier. By the tenth, it’s almost trivial. Each new agent plugged into the Hub inherits the work you’ve already done. The ecosystem becomes self-reinforcing.
This is how AI in banking scales — not through heroic, bespoke implementations of individual capabilities, but through a composable ecosystem where every agent speaks the same language, grounded in one truth.

Start with the Business Case, Not the Architecture
If there’s one piece of advice I give consistently — in every interview, every keynote, every conversation with a bank executive — it’s this: don’t start with the architecture. Start with the business case.
Don’t walk into a steering committee and say “we need Headless BI.” Walk in and say “we want to increase product holding ratio by 20% within 18 months” or “we want to reduce churn among digitally inactive customers by 30%.” Scope the problem. Quantify the opportunity. Make the ROI conversation concrete.
Then — and only then — let the architecture follow.
The Customer Lifetime Orchestrator’s 90-day plan is a perfect scoped entry point. Pick one product category — credit card activation, for example. Define the governed metrics you need: activation rate, engagement score, propensity model inputs. Stand up the semantic layer for those specific metrics. Deploy the orchestration. Measure the impact.
Once it works — once you can demonstrate that a governed, headless intelligence layer feeding AI agents produces measurably better outcomes than the old “blast and pray” campaigns — you have the evidence to expand. Add the Financial Wellbeing Coach. Onboard a second product category into the CLO. Start exploring the AI Hub for pre-built agents that accelerate your next use case.
This is progressive modernization. It’s the same principle that guides how we think about platform transformation at Backbase: you don’t need to boil the ocean. You need to prove value in a contained scope, then scale deliberately.
I’m very much against it when people talk about “traditional banking versus AI banking.” There’s no such thing — it’s only banking. The more technology evolves, the more ways you have to serve your customers. But remember that AI is just a tool that helps you achieve that goal. Headless BI is just an architecture that makes that tool reliable.
The banks that get this right won’t be the ones with the most impressive AI demos. They’ll be the ones where every agent and every dashboard tells the same story — and where that story drives measurable business outcomes.
The metrics are ready to be set free. The question is whether your bank is ready to let them.
Pure Headless BI / Semantic Layer Platforms
Cube — The most established dedicated headless BI platform. Open-source core (Apache 2.0), with a commercial Cube Cloud offering. You define metrics and data models in code (YAML or JavaScript), and expose them via REST, GraphQL, and SQL APIs to any downstream consumer — dashboards, custom apps, AI agents. It includes built-in caching, pre-aggregations, access control, and an MCP server so AI agents can call governed metrics as tools. Works with any front-end (Superset, Metabase, Retool, React, etc.) and integrates with dbt. This is probably the closest to what the term “Headless BI” was coined to describe.
dbt Semantic Layer (MetricFlow) — dbt Labs acquired Transform (the original MetricFlow creators) and built the dbt Semantic Layer on top of it. You define metrics in YAML alongside your dbt transformation models, and MetricFlow compiles metric requests into optimized SQL at query time. MetricFlow was recently open-sourced, and dbt Labs has joined the Open Semantic Interchange (OSI) initiative to make definitions portable across tools. dbt Labs The catch: the API that lets BI tools query those metrics is a paid dbt Cloud feature — it’s not available in dbt Core. Strong integrations with Tableau, Looker, Hex, and ThoughtSpot.
AtScale — Enterprise-grade universal semantic layer. Defines metrics, hierarchies, and business logic once and exposes them to BI tools, AI agents, and LLMs. It connects directly to cloud data warehouses and supports MCP for agentic AI workflows. AtScale Introduced SML (Semantic Modeling Language), an open standard for portable metric definitions. Can ingest models from dbt, Power BI, and LookML. Best suited for large enterprises. No public pricing — enterprise sales model.
GoodData — Commercial platform with a strong headless BI positioning. Offers a rich semantic layer with its Logical Data Model (LDM) and MAQL query language. Any data tool can access the platform and consume metrics via open APIs, SDKs, and standard protocols — including a PostgreSQL interface for end users. GoodData Supports multitenancy, access control, and headless embedding. Has a free tier.
Kyvos — Positions itself as a semantic intelligence layer for AI and BI at massive scale. Focuses on blazing-fast analytics on hundreds of billions of rows, OLAP modernization, and serving as a single source of semantic truth for agents, LLMs, and BI. Kyvos Insights Enterprise-focused, works across Snowflake, Databricks, BigQuery, Redshift.
Looker (Google) — The pioneer of code-based semantic modeling with LookML. Historically tightly coupled (your LookML definitions lived inside Looker), but Google is reportedly working on separating the modeling layer so LookML can be used in a headless architecture. If you’re already in the Google Cloud ecosystem, this is significant.
Holistics — A “BI as code” platform with its own semantic modeling language (AMQL). It mixes drag-and-drop dashboards with Git-based version control for data models, supporting CI/CD, data unit testing, and DAG-based dependency tracking. Holistics Strong semantic layer that sits between the warehouse and visualization, with the modeling layer versioned in Git.
Lightdash — Open-source, Git-native BI that connects directly to dbt models. You define metrics once in dbt and expose them through Lightdash’s UI. Has an open-source semantic layer built in and integrates with the dbt Semantic Layer. Best for teams already deep in the dbt ecosystem.
ThoughtSpot — Known for natural-language search-based analytics. Has a strong embedded/headless offering (ThoughtSpot Embedded) where you can serve insights via APIs into custom applications. Positions itself as a headless BI option for customer-facing analytics.
Power BI (Microsoft) — Not traditionally headless, but the semantic model (DAX/tabular model) is increasingly accessible externally. Microsoft recently released a public preview of a Power BI Modeling MCP Server, signaling a move to open up their ecosystem to external agents. VentureBeat Semantic Link (SemPy) lets Python notebooks mount Power BI datasets as DataFrames. If your bank is a Microsoft shop, this is the pragmatic path.
Snowflake — Building native semantic/metric views into the platform. The definitions live next to the data, enabling zero-copy access. Supports governed, YAML-based metric definitions.
Databricks (Unity Catalog) — Similar approach — governed metric definitions within the lakehouse. Powers internal AI chatbots and ensures a single source of truth within the Databricks ecosystem.
Dremio — Open lakehouse platform that functions as a universal semantic layer. Defines business logic via virtual datasets (SQL views), and offers APIs including ODBC, JDBC, Arrow Flight, and REST. An AI agent reads Dremio’s wikis and labels to generate accurate SQL from natural language, while dashboards and notebooks connect through the same governed definitions. Datalakehousehub
These aren’t headless BI themselves, but they’re commonly used as the visualization consumer on top of a headless semantic layer like Cube or dbt:
Apache Superset — The most popular open-source dashboarding tool. Integrates well with Cube via SQL API. Often used in the dbt → Cube → Superset stack.
Metabase — Open-source, known for simplicity. Can sync with dbt models and consume from Cube’s SQL API.
Evidence — “BI as code” — you write reports in SQL + Markdown, rendered into polished pages. Git-versioned, production-ready. A natural fit for headless architectures.
Redash — Lightweight open-source dashboarding. Good for quick SQL-based reporting on top of a governed semantic layer.
Worth noting: the initiative launched in 2025 is trying to create a vendor-neutral standard for portable metric definitions. Both dbt Labs and Cube have joined. This is the interoperability layer that could make it possible to define metrics once and have them consumed by any tool — exactly the promise of Headless BI.


