Something I keep running into while building AI agents for banking.
The demo always works. An LLM calls a few APIs, pulls customer data, generates a recommendation, maybe sends a nudge. Three-minute video. Looks incredible. Everyone in the room nods.
Then you try to put it in production. And you discover that the hard problems were never language problems.
They’re problems like: should the agent act right now, or wait? The customer’s salary just dropped 20% — is that a job loss or a career transition? The answer changes everything about what the agent should do next. An LLM processing that signal in isolation will generate a plausible response. But plausible isn’t the same as right.
Or: the agent recommended a product last Tuesday. The customer ignored it. Does the agent try again? Rephrase? Back off entirely? This isn’t a reasoning problem — it’s a state and memory problem. The agent needs to remember not just what it said, but what happened after it said it, and update its model of this customer accordingly.
Or the hardest one: consequence. If the agent nudges a customer to move savings into a term deposit and rates drop the following week, was that good advice? The agent needs some internal model of what might happen next — not just what’s statistically likely in the training data.
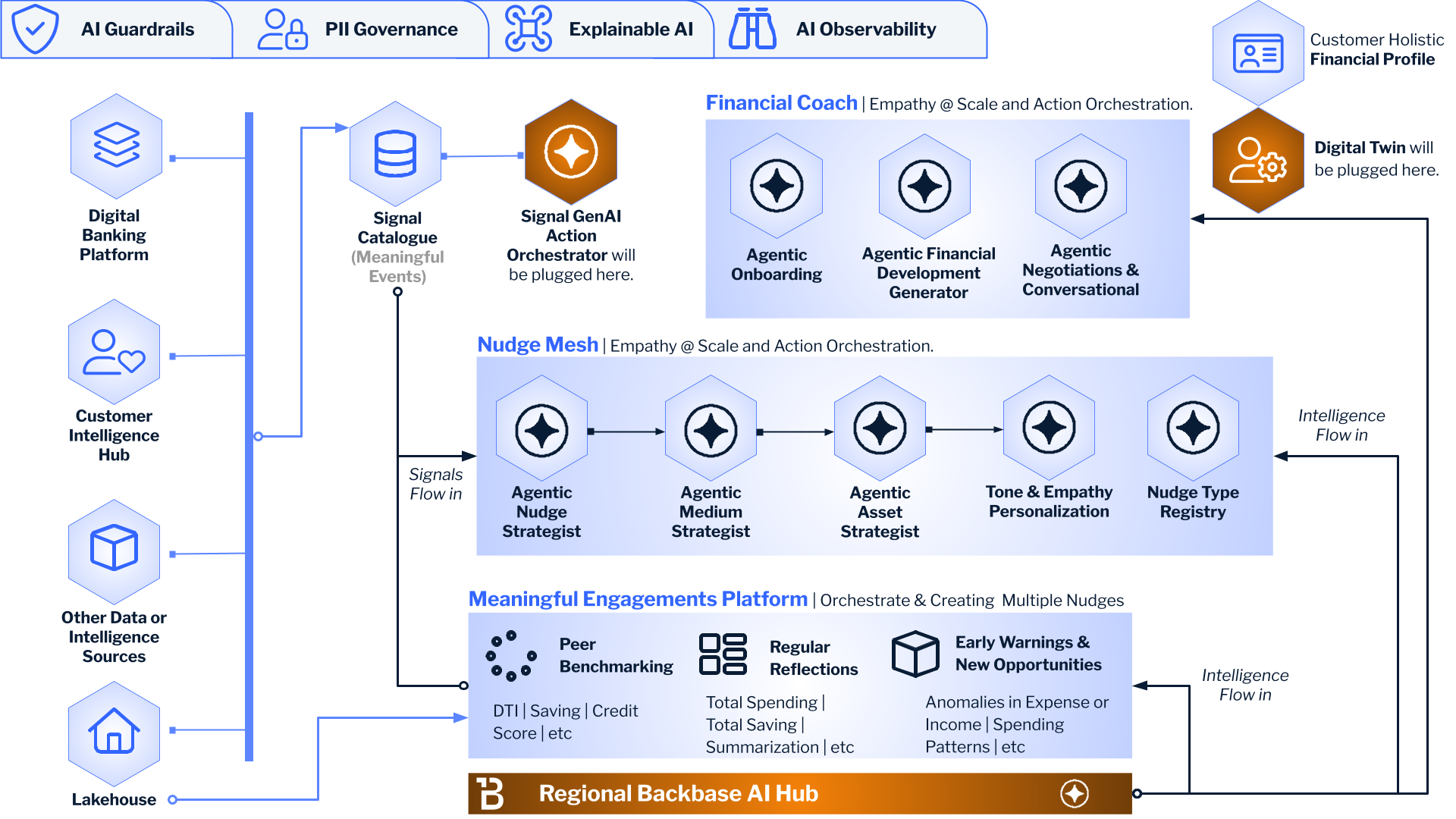
We hit all of these walls building the Intelligence Layer at Backbase. And what we found is that the LLM is essential but insufficient. It’s the linguistic engine — phenomenal at understanding intent, generating responses, reasoning through complex scenarios in natural language. But it needs architecture around it.
A Signal Catalogue that detects meaningful events and distinguishes noise from signal. A Digital Twin that maintains a persistent, evolving picture of each customer’s full financial life. A Nudge Mesh that orchestrates when to act, which channel to use, what tone to strike — and critically, when to stay silent. None of these are LLM problems. They’re systems problems.
The gap between an agent demo and an agent in production isn’t model quality. It’s everything around the model.
I think the industry will figure this out over the next 18 months, mostly the hard way. The teams that start with the architecture and plug LLMs into the right places will ship agents that actually work. The teams that start with the LLM and try to bolt on memory, state, and consequence modeling after the fact will keep producing impressive demos that never quite make it to production.
At least, that’s what the walls we hit taught us. Curious whether others are seeing the same pattern.


